There are many forms of parallelism and concurrency which can be applied to advanced computational problems in robot control and simulation. This fact leads to the developments of many parallel architectures that utilizes this property.
A real-time robot control based on multi-processor architecture was proposed in [1]. in this design the control tasks are analyzed to obtain a lower bound on the number of mathematical operations required to generate the control signal, then a parallel computation structure is designed according to the maximum sample time based on the stability of the control system. This design can be implemented as a custom VLSI or as a systolic array based system.
An optimal design for multiple-APU (Arithmetic Processing Unit) based robot controllers is discussed in [2]. In this paper it was shown that using eight APUs, it is possible to compute the inverse kinematics, inverse dynamics and the trajectory for the PUMA arm in less than 3ms using 16.7 MHZ 68881.
A dataflow multiprocessor system for robot arm control was proposed in [15]. In this method, the maximum parallelism would require 1834 processing elements. However, a reasonable engineering solution requires 42 processing elements.
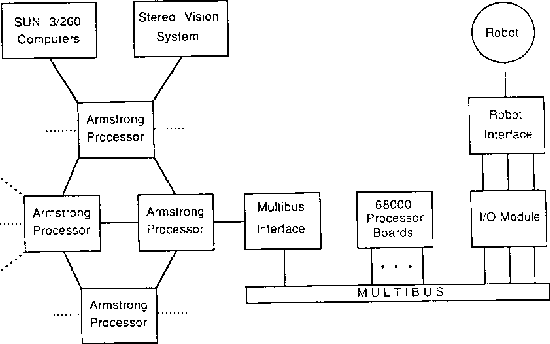
SIERA (System for Implementing and Evaluating Robotic Algorithms) is a multiprocessor system that has been developed at the Laboratory for Engineering Man/Machine Systems (LEMS) at Brown University. It incorporates a tightly coupled bus-based system (the Real-time Servo System) and a loosely coupled point-to-point network (the Armstrong Multiprocessor System). Figure 5 shows an overview of the SIERA system and Figure 6 shows the Armstrong processes. More details can be found in [22].
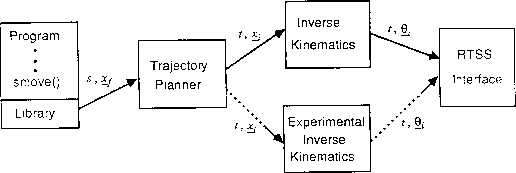
Figure 6: Armstrong processes.
A parallel computer architecture for real-time control application in grasping and manipulation was proposed in [26]. In this paper a new scheduling algorithm for multiprocessor architecture based on either complete or incomplete crossbar interconnection networks is presented. The mean feature of the proposed algorithm is that it takes into account the communication delays between processors and minimizes both the execution time and the communication cost.
Several parallel architectures are proposed in [35, 36, 43, 47, 55]