| |
|
|
|
|
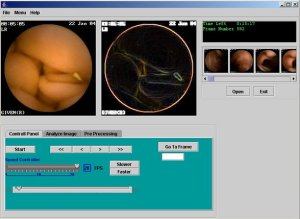 Wireless
Capsule Endoscopy (WCE) Videos Wireless
Capsule Endoscopy (WCE) VideosWireless Capsule
Endoscopy (WCE) allows a physician to examine the entire small
intestine without surgical operation. However, reviewing WCE video
is tedious and labor intensive due to the lengthy video with a great
amount of redundant frames. To improve the diagnosis efficiency and
accuracy, it is necessary to reduce the video evaluation time and to
develop (1) techniques to automatically discriminate digestive
organs such as esophagus, stomach, duodenum, small intestine, and
colon; (2) efficient reviewing methods that greatly reduces the time
without sacrificing the diagnosis accuracy; and (3) techniques to
automatically find abnormal regions (e.g. bleeding).
To address these needs, we have developed (1) a novel technique
to segment a WCE video based on color change pattern analysis; (2) a
similarity-based frame comparison technique to distinguish novel and
redundant frames; and (3) a technique to automatically detect
bleeding regions using Expectation Maximization (EM) clustering
algorithm, respectively. We present the experimental results that
demonstrate the effectiveness of our methods.
Click to see WCE video clip [ WCE.avi 3.3
MB ] |
| |
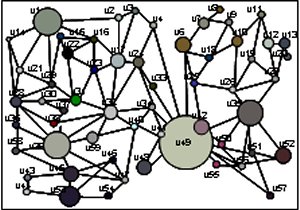 Graph-based
Approach of Modeling and Indexing Videos Graph-based
Approach of Modeling and Indexing VideosEarly video
database systems segment video into shots, and extract key frames
from each shot to represent it. Such systems have been criticized
for not conveying much semantics and ignoring temporal
characteristics of the video. Current approaches only employ
low-level image features to model and index video data, which may
cause semantically unrelated data to be close only because they may
be similar in terms of their low-level features. Furthermore, such
systems using only low-level features cannot be interpret as
high-level human perceptions. In order to address these, I propose a
novel graph-based data structure, called Spatio-Temporal Region
Graph (STRG), which represents the spatio-temporal features and
relationships among the objects extracted from video sequences.
Region Adjacency Graph (RAG) is generated from each frame, and an
STRG is constructed from RAGs. The STRG is decomposed into its
subgraphs, called Object Graphs (OGs) and Background Graphs (BGs) in
which redundant BGs are eliminated to reduce index size and search
time. Then, OGs are clustered using Expectation Maximization (EM)
algorithm for more accurate indexing. To cluster OGs, I propose
Extended Graph Edit Distance (EGED) to measure a distance between
two OGs. The EGED is defined in a non-metric space first for the
clustering of OGs, and it is extended to a metric space to compute
the key values for indexing. Based on the clusters of OGs and the
EGED, I propose a new indexing method STRG-Index that provides
faster and more accurate indexing since it uses tree structure and
data clustering.
The proposed STRG model is applied to other video processing areas:
i.e., video segmentation and summarization. The result of video
segmentation using graph matching outperforms existing techniques
since the STRG considers not only low-level features of data, but
also spatial and temporal relationships among data. For the video
summarization, Graph Similarity Measure (GSM) is proposed to compute
correlations among the segmented shots. A video can be summarized in
various lengths and levels using GSM and generated scenarios.
Click to see captured video for STRG generation [
STRG.avi 2.3 MB ] |
| |
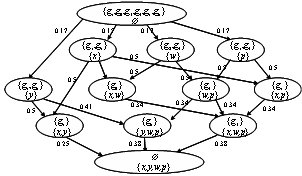 Automatic
Generation of Multimedia Ontology Automatic
Generation of Multimedia OntologyWhat existing
multimedia databases miss is the concept of the data that can bridge
the gap between low-level features and high-level human
understandings. For example, a red color is represented by RGB color
values as (255, 0, 0). However, those who do not have any prior
knowledge of RGB color domain cannot understand the values as a red.
Current approaches use manually annotated text data to describe the
low-level features. However, such manual operations are very
subjective, and even time consuming tasks. In this research, I
employ ontology to manage the concepts of multimedia data, and to
support high-level user requests, such as concept queries.
In order to generate the ontology automatically, I propose a
model-based conceptual clustering (MCC) based on a formal concept
analysis. The proposed MCC consists of three steps: model formation,
model-based concept analysis, and concept graph generation. We then
construct ontology for multimedia data from the concept graph by
mapping nodes and edges into concepts and relations, respectively.
In addition, the generated ontology is used for a concept query that
answers a high-level user request. The model-based conceptual
clustering and automatic ontology generation techniques can be
easily applied to other spatial and temporal data, i.e., moving
objects in video, hurricane track data, and medical video. |
| |
|
|
| |
|
Analysis of TaeKwonDo Movement |
| |
|
|
| |
|
Vlinkage: Video Copy Detection |
| |
|
|
| |
|
BLASTed Image Matching |
| |
© Copyright 2007 MIG@UB
e-Mail:
jelee@bridgeport.edu |
|
| | |
|